阿里云ONS配置问题导致外网启动慢的问题查询
现象
业务中用到了阿里云的ONS服务,开发中相同配置的情况下,在外网环境(mac开发机)上与阿里云ecs服务器上,服务启动时间相差巨大 (11.124 seconds与23.863 seconds的差距,相差接近10秒),查看日志并没有发现任何error出现,但是有一个奇怪的现象是,就是在外网环境启动时,两条日志记录的间隔时间也差不多是10秒左右。
解决思路
此时考虑,可能是main线程在这两条日志记录中间有耗时操作。于是打开VisualVM对java进程进行了thread dump。dump结果如下:
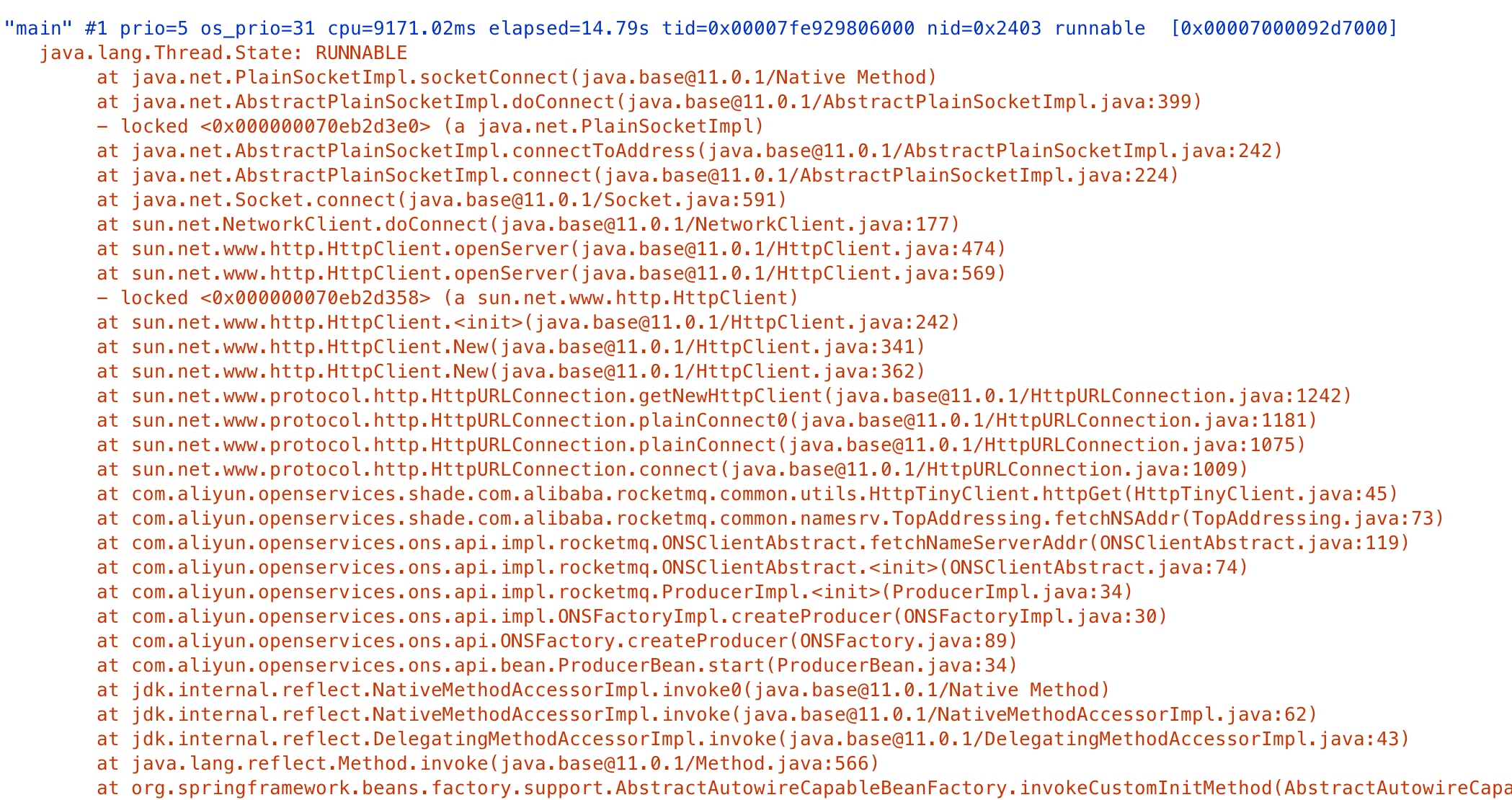
可以看到,调用栈在sun.net.www.http.HttpClient处锁住了,调用方是com.aliyun.openservices.shade.com.alibaba.rocketmq.common.utils.HttpTinyClient.httpGet 既然找到了位置,那么就可以加断点调试了。
加断点后调试查询发现,ons启动时会默认连接两个地址http://onsaddr-internet.aliyun.com/rocketmq/nsaddr4client-internet与http://onsaddr-internal.aliyun.com:8080/rocketmq/nsaddr4client-internal,前一个地址从url中可以看出就是个外网访问地址,但是后一个地址是一个内网地址。这样在外网环境下连接时会因为连接不上而超时,超时时间默认设置又是5秒,这也与项目中使用了两个队列相吻合。
解决方式
既然是默认连接两个地址,那么自然应该会有配置来设置只连内网或者只连外网。
private fun initProperties(): Properties {
val properties = Properties()
properties.setProperty(PropertyKeyConst.AccessKey, messageQueueProperties.accessKey)
properties.setProperty(PropertyKeyConst.SecretKey, messageQueueProperties.secretKey)
// 注意,一定要传这个值,否则外网启动会慢到死
//properties.setProperty(PropertyKeyConst.ONSAddr, messageQueueProperties.onsAddr)
return properties
}
这是我们配置ons的函数,可以看到默认是,是不设置PropertyKeyConst.ONSAddr这个配置的,这样ons启动时就会内网地址与外网地址同时连接。但是配置后,就只会连接设置的messageQueueProperties.onsAddr地址了。搭配spring的profile进行环境区分,不同环境配置不同的onsAddr就可以完美解决这个问题了。
InnoDB行锁的实现方式
实现方式
与Oracle的行锁不同,MySql的InnoDB行锁锁定的数据是对应的索引,而不是对应的行数据,也就是说,当检索条件不通过索引时,InnoDB将使用表锁进行锁定。实际应用中,如果不考虑这种情况,可能会造成大量的表锁冲突,影响并发性能。
示例
创建一个测试表并写入测试数据
create table innodb_lock (id int,name varchar(20));
insert into innodb_lock values(1,'a'),(2,'b'),(3,'c'),(4,'d');
注意:此时并没有创建索引。
mysql> select * from innodb_lock;
+------+------+
| id | name |
+-------------+
| 1|a |
| 2|b |
| 3|c |
| 4|d |
+-------------+
4 rows in set (0.01 sec)
无索引情况
-
终端启动两个mysql客户端连入数据库
-
两个终端各自开启一个事务
mysql> start transaction; Query OK, 0 rows affected (0.00 sec)为了方便起见,下文将两个事务分别命名为事务A与事务B
-
事务A 运行update命令修改id为4的数据的name列为e
mysql> update innodb_lock set name='e' where id=4; Query OK, 1 row affected (0.07 sec) Rows matched: 1 Changed:1 Warnings:0 mysql>注意此时事务A并没有提交事务。
-
事务B 同样运行update命令修改id为1的数据的name列为e
mysql> update innodb_lock set name='e' where id=1;执行此命令后,客户端会卡在获取锁的阶段上。并没有直接返回。说明此时事务A已经锁住了整张表,与我们的预期一致。
当事务B等待锁的时间超过innodb_lock_wait_timeout时,事务B会返回如下错误:mysql> update innodb_lock set name='e' where id=1; ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactioninnodb_lock_wait_timeout的默认设置为50秒。
-
事务A运行commit命令提交事务
mysql> commit; Query OK, 0 rows affected (0.00 sec)此时观察事务B的返回会发现事务B的update操作也成功返回了。代表事务B获取到了表锁。
事务B返回如下所示mysql> update innodb_lock set name='e' where id=1; Query OK, 1 row affected (4.08 sec) Rows matched: 1 Changed: 1 Warnings: 0从事务B的运行时间4.08sec也可以看出来事务B确实在获取锁时进行了等待
有索引的情况
-
相同的表结构与数据,但是增加了id为索引。
mysql> alter table innodb_lock add index id_idx(id); Query OK, 0 rows affected (0.21 sec) Records: 0 Duplicates: 0 Warnings: 0 -
两个终端各自开启一个事务
mysql> start transaction; Query OK, 0 rows affected (0.00 sec)为了方便起见,下文将两个事务分别命名为事务A与事务B
-
事务A 运行update命令修改id为4的数据的name列为e
mysql> update innodb_lock set name='e' where id=4; Query OK, 0 rows affected (0.03 sec) Rows matched: 1 Changed: 0 Warnings: 0 mysql>此时事务A同无索引情况一样并没有提交事务。
-
事务B 同样运行update命令修改id为1的数据的name列为e
mysql> update innodb_lock set name='e' where id=1; Query OK, 0 rows affected (0.00 sec) Rows matched: 1 Changed: 0 Warnings: 0 mysql>
可以发现,事务B并没有像无索引情况下那样阻塞住,而是马上返回了运行结果,说明此时事务A与B的锁粒度是行锁,而并不是表锁。同样可以说明MySql的行锁实现方式实际上是锁的索引而并不是行数据。
总结
MySql的行锁实现方式是对对应的索引进行锁定,而不是对对应的行进行锁定。如果命令并不是通过索引的方式进行锁定,那么锁将膨胀为表锁,此时在大并发量下会造成大量的锁等待,影响服务性能。
开启BBR
因为BBR的关系,最近更新了一下VPS(debian)的kernel到4.9+以支持BBR。特将更新步骤记录下来。
写在前面
关于BBR的原理可以参考知乎上的一个回答。
下载最新kernel
在http://kernel.ubuntu.com/~kernel-ppa/mainline/ 中下载最新的kernel。
这次我下载的是4.10的kernel,直接在终端中输入命令
wget http://kernel.ubuntu.com/\~kernel-ppa/mainline/v4.10/linux-image-4.10.0-041000-generic_4.10.0-041000.201702191831_amd64.deb即可
安装kernel
运行命令
dpkg -i linux-image-4.10.0-041000-generic_4.10.0-041000.201702191831_amd64.deb后面的deb名称要根据你第一步下载的kernel而定。
(可选)删除其余kernel
查找内核
dpkg -l|grep linux-image 删除上面列出的非此次安装的kernel
apt-get purge 旧内核更新 grub 系统引导文件并重启
终端运行
update-grub
reboot开启BBR
echo "net.core.default_qdisc=fq" >> /etc/sysctl.conf
echo "net.ipv4.tcp_congestion_control=bbr" >> /etc/sysctl.conf
sysctl -p执行
sysctl net.ipv4.tcp_congestion_control
net.ipv4.tcp_congestion_control = bbr如果结果中有bbr则证明你的vps已经开启了bbr
执行
lsmod | grep bbr
tcp_bbr 20480 78最后
我的VPS使用的是StarryDNS的大阪机房。
北京联通直连不跳北美。想体验StarryDNS的可以通过这个链接来注册。
Copyright © 2015 Powered by MWeb, Theme used GitHub CSS.